탠서플로를 통한 자동차 연비 예측하기 공식 문서 (링크)
필요한 도구 가져오기
# 데이터 분석을 위한 pandas, 시각화를 위한 seaborn 불러오기
import pandas as pd
import seaborn as sns
데이터셋 로드하고 결측치 확인
- 머신러닝, 딥러닝으로 데이터 예측할 때는 연산작용을 통해서 결과값이 출력되는 것
- 그런데, 결측치가 있으면 그 데이터는 계산할 수 없기 때문에 결측치를 제거하거나 대체해야함
- 결측치가 많지 않으면 제거하면 되고, 결측치가 너무 많다면 다른 값으로 대체하는게 적절
# 자동차연비 데이터셋인 mpg 데이터셋을 불러옵니다.
df = sns.load_dataset('mpg')
df.shape
(398, 9)
# 결측치의 합계 구하기
df.isnull().sum()
mpg 0
cylinders 0
displacement 0
horsepower 6
weight 0
acceleration 0
model_year 0
origin 0
name 0
dtype: int64
결측치 제거 : dropna
# dropna로 결측치를 제거합니다.
df= df.dropna()
df
수치 데이터만 가져오기
- 머신러닝이나 딥러닝 모델은 내부에서 수치계산을 하기 때문에 숫자가 아닌 데이터를 넣어주면 모델이 학습과 예측을 할 수 없음
# select_dtypes 를 통해 object 타입을 제외하고 가져옵니다.
df = df.select_dtypes(exclude='object')
df
데이터셋 나누기
- 전체 데이터프레임에서 train용 데이터셋과 test용 데이터셋으로 분리
- train_dataset : 학습에 사용 (예: 기출문제)
- test_dataset : 실제 예측에 사용 (예 : 실전문제)
- 기출문제로 공부하고 실전 시험을 보는 과정과 유사
1️⃣ train_dataset 만들기
- 전체 데이터셋 중에서 80퍼를 샘플로 추출해라 → train에 지정
train_dataset = df.sample(frac=0.8, random_state=42)
train_dataset.shape
2️⃣ test_dataset 만들기
- 그냥 따로 또 sample을 사용해서 테스트 데이터셋으로 분리하면 겹치는게 있을 수도 있음 😱
- 그래서 위에서 만든 train 데이터셋을 전체데이터에서 빼면 돼!! => 아예 빼버릴 때는 drop 이용
test_dataset = df.drop(train_dataset.index)
test_dataset.shape
문제에서 정답(label)을 분리하기
- train_dataset, test_dataset 에서 label(정답) 값을 꺼내 label 을 따로 생성합니다.
- 우리 데이터에서는 전체 데이터에서 mpg(예측할 값)칼럼을 따로 빼야해
- pop : 특정 데이터 칼럼만 뽑아줘
- 그 전 데이터프레임에선 아예 없어지는거. 아예 다 떼버려

# train 데이터셋의 mpg값만 추출
train_labels = train_dataset.pop('mpg')
train_labels
# test 데이터셋의 mpg값만 추출
test_labels = test_dataset.pop('mpg')
test_labels이렇게 pop으로 정답 칼럼을 따로 빼내고, 원래 데이터 셋을 확인해보면?
train_dataset.shape, test_dataset.shape
((314, 6), (78, 6))칼럼 수가 7개에서 6개로 줄었다!!! 🌟
여기서 잠깐 정리하자면,,
train_dataset에 연비를 제외한 나머지 컬럼들이 있는데, 그 나머지 컬럼들을 학습해서
test_datset에서 연비가 얼마인지를 예측을 한다!
[딥러닝 모델 만들기]
- 두 개의 완전 연결(densely connected) 은닉층으로 Sequential 모델을 만들겠습니다.
- 출력 층은 하나의 연속적인 값을 반환합니다.

# tensorflow 를 불러옵니다.
import tensorflow as tf
tf.__version__
1️⃣ 딥러닝 층 구성
- Dense layer에 들어가는 숫자는 유닛의 개수를 의미,, 임의로 지정해주면 돼
- input_shape : 입력하는 변수의 개수 (=train_dataset의 칼럼 개수=6)
model = tf.keras.Sequential()
model.add(tf.keras.layers.Dense(64, input_shape=[len(train_dataset.keys())])) # 입력층
model.add(tf.keras.layers.Dense(64)) # 히든 레이어 1
model.add(tf.keras.layers.Dense(64)) # 히든 레이어 2
model.add(tf.keras.layers.Dense(1)) # 출력층
2️⃣ 모델 컴파일 : 모델을 학습시키기 위한 학습과정을 설정하는 단계
- metrics : 우리가 만든 모델의 정확도 어느정도 되는지 측정하는 여러가지 방법
-
- MAE(Mean Absolute of Errors) : 평균 절대 오차
- 예측값 - 관측값들의 제곱이 아니라 '절댓값' 을 통해 음수를 처리한 뒤 이들의 평균
→ 제곱을 하지 않아서 단위 자체가 기존 데이터와 같아 회귀 계수 증감에 따른 오차를 쉽게 파악할 수 있음 - 오차에 대한 절댓값의 평균
- 오차가 0에 가까울수록 정확도가 높구나~ 판단
- 예측값 - 관측값들의 제곱이 아니라 '절댓값' 을 통해 음수를 처리한 뒤 이들의 평균
- MSE(Mean Square of Errors) : 평균 제곱 오차
- 예측값 - 관측값의 제곱된 값의 평균
- 제곱으로 인해 원래 차이보다 다소 민감한 성능평가일 수 있음
- 선형 회귀의 평가 지표 참고 링크회귀에서는 'mae', 'mse' 방법을 많이 사용하는 편
- MAE(Mean Absolute of Errors) : 평균 절대 오차
-
model.compile(loss='mse', metrics = ['mae', 'mse'])
3️⃣ 만든 모델 확인하기
model.summary()
4️⃣ 딥러닝 모델로 학습하기
- fit : 트레이닝 데이터와 레이블을 가지고 학습을 한다~
- epochs : 몇 번 반복해서 학습할건지 입력
- verbose: 로그를 어떻게 찍을건지를 의미 ➡️ 0 으로 하면 로그 출력 안함
model.fit(train_dataset, train_labels, epochs = 100, verbose = 0)
5️⃣ 딥러닝 모델 평가하기
- 모델 직접 컴파일할 때 지정한 오차 측정방법을 통해서 오차를 구함
- 평가 방법
- 자동차 연비를 예측을 하는데 평균적으로 절댓값이 7정도가 차이가 난다 평가
- 에러값을 제곱해서 평균을 구한게 75정도 된다.
model.evaluate(test_dataset, test_labels)
3/3 [==============================] - 0s 5ms/step - loss: 75.1122 - mae: 7.5044 - mse: 75.1122
[75.11222839355469, 7.504369258880615, 75.11222839355469]
6️⃣ 딥러닝 모델의 예측하기
- 2차원 형태로 결과가 나와서 한줄로 보고싶다면? flatten() 사용
predict_labels = model.predict(test_dataset).flatten()
predict_labels[:5]
3/3 [==============================] - 0s 3ms/step
array([ 9.417114, 3.280769, 20.84774 , 19.498169, 11.095715],
dtype=float32)
7️⃣ 딥러닝 모델의 예측결과 평가하기
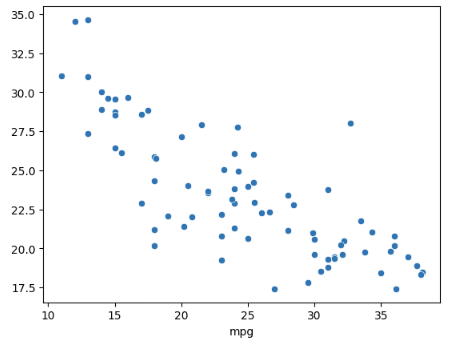
- 잘 예측했으면 mpg값이 우 대각선이 그려져서 실제값과 예측값이 상관이 되어야한다.
- 근데 우리 그림은 제대로 학습이 안된 것 같아 ➡️ 모델을 개선하면서 오차 값을 점점 줄여야 해
sns.scatterplot(x=test_labels, y=predict_labels)
[모델 개선하는 방법 ]
- 1. 학습 반복 횟수(epoch) UP
- epoch 횟수 10번만 학습하는게 아니라 100번 정도 학습시켜라 → mae 값이 줄어들었음
- 2. 딥러닝 층 구성 할 때, activation = 'relu' 추가
- 출력층에는 넣지 말고 입력층과 히든층에만
- 3. 레이어의 수를 변경해보거나 레이어 안의 유닛개수를 조정해본다
# 실제 값이 증가함에 따라 예측값도 증가하고 있군!
sns.jointplot(x=test_labels, y=predict_labels, kind = 'reg')
'👩🏻💻 강의 기록용 > 처음 시작하는 데이터 사이언스' 카테고리의 다른 글
| 6-① 탠서플로우를 통한 데이터 예측 (0) | 2023.09.19 |
|---|---|
| 05-④ 파이썬 EDA - 범주형 변수 (0) | 2023.09.17 |
| 05-③ 파이썬 EDA - 수치형 변수 (0) | 2023.09.17 |
| 05-② 판다스 기초와 데이터 요약, 탐색적 데이터 분석 도구 사용하기 (0) | 2023.09.17 |
| 05-① 파이썬 탐색적 데이터 분석 도구 (0) | 2023.09.12 |



