기술 통계
# describe 를 통해 범주형 변수에 대한 기술통계를 보기
df.describe(include='object')
- count : 빈도수
- unique : 중복 제외한 유일한 값들의 빈도 수
- top : 최빈값, 가장 빈번하게 나온 값의 정체는?
- freq : 위에서 최빈값의 빈도수. 총 몇번이나 나왔어~
범주형 데이터의 유일값의 빈도수
# nunique 값 구하기
df.nunique()
mpg 129
cylinders 5
displacement 82
horsepower 93
weight 351
acceleration 95
model_year 13
origin 3
name 305
countplot 으로 origin 빈도수 시각화 하기
- x='origin' : 아래 그림처럼 세로로 보여주는거고
- y='origin' : 바그래프를 가로로 볼 수 있는 기능
sns.countplot(data=df, x='origin')
내가 원하는 칼럼의 유니크한 빈도수가 궁금할 때 (# 변수가 하나일 때)
# origin 하나의 변수의 빈도수 구하기
df['origin'].value_counts()
usa 249
japan 79
europe 70
내가 원하는 칼럼의 유니크한 빈도수가 궁금할 때 (# 변수가 2개 이상일 때) ➡️ crosstab
- 시리즈 형태의 값을 인덱슬와 컬럼스로 지정하면 각 빈도수를 크로스탭으로 보여주게 됨
- 하나의 변수의 빈도수를 구할때는 value_count, 두개의 변수에 대한 빈도수를 구할때는 crosstab
pd.crosstab(df['origin'], df['cylinders'])
빈도수 시각화
# countplot 으로 origin 의 빈도수를 시각화 하고 cylinders 로 다른 색상으로 표현하기
sns.countplot(data=df, x='origin', hue='cylinders')
1. groupby 를 통한 연산 → 데이터프레임으로 나타내기
- groupby를 통해 origin 별로 그룹화하고 mpg의 평균 구하기
- .unstack( ) 을 하면 데이터 프레임으로 만들어줌!
df.groupby('origin')['mpg'].mean().unstack()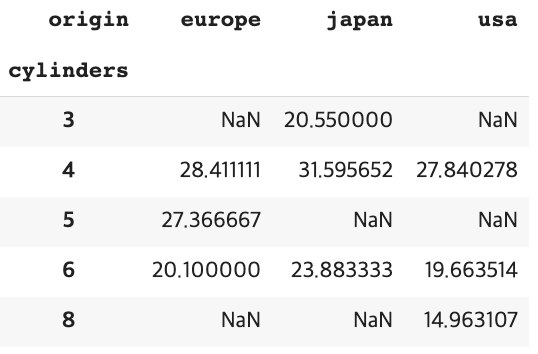
2. pivot table
- 연산할 때 그룹바이로도 구할 수 있고 피봇으로도 구할 수 있음
- crosstab도 빈도 수 구할 수 있는데, 그건 피봇보다 더 쉽게 만들어준 한번 더 감싸준 기능이다!
pd.pivot_table(data=df, index='origin', values='mpg')
# 그냥 이렇게만 하면 모든 수치변수에 대한 평균값을 구하게 돼
pd.pivot_table(data=df, index='cylinders', columns='origin')
# mpg값에 대해서만 피봇 구하게 됨
pd.pivot_table(data=df, index='cylinders', columns='origin', values='mpg')
boxplot으로 origin 별 mpg 의 기술통계 값 구하기
# 연비가 오리진 값에 따라서 어느정도 차이가 나는지 그려볼 수 있음
sns.boxplot(data=df, x='origin', y='mpg')
박스플랏의 값들을 찾아보자..
# groupby로 origin 값에 따른 mpg의 기술통계 구하기
df.groupby('origin')['mpg'].describe()
그럼 이상치는 어떻게 구한거야??

# IQR, 이상치를 제외한 최댓값, 최솟값 구하기
Q3 = europe['75%']
Q1 = europe['25%']
IQR = Q3-Q1
OUT_MAX = Q3 + (1.5 * IQR)
OUT_MIN = Q1 - (1.5 * IQR)
OUT_MAX, OUT_MIN
(40.625, 14.025000000000002)저 OUT_MAX보다 크거나, OUT_MIN보다 작으면 이상치! 라고 판단하는 것
박스플롯의 단점
- 박스 안에 값이 변화가 되거나 수염에 있는 값의 분포가 어떻게 되어있는지 알기가 어렵다!
boxenplot 그리기 : 수염부분 디테일하게
sns.boxenplot(data=df, x='origin', y='mpg')
violinplot 그리기
sns.violinplot(data=df, x='origin', y='mpg')
산점도를 통한 범주형 데이터 표현
- scatterplot
- 적합하지 않다!
- 겹쳐서 찍히는게 많아서 데이터가 어디에 어느정도 분포가 되어있는지 제대로 파악하기 어려움
# scatterplot 으로 범주형 변수 그리기
sns.scatterplot(data=df, x='origin', y='mpg')
- stripplot
- 스캐터보다 옆으로 흩뿌려서 그리게 되어있음
- 어디에 몰려있는지 상대적으로 더 잘 확인 가능 → 하지만, 여전히 겹치는 부분이 많다면?
# stripplot
sns.stripplot(data=df, x='origin', y='mpg')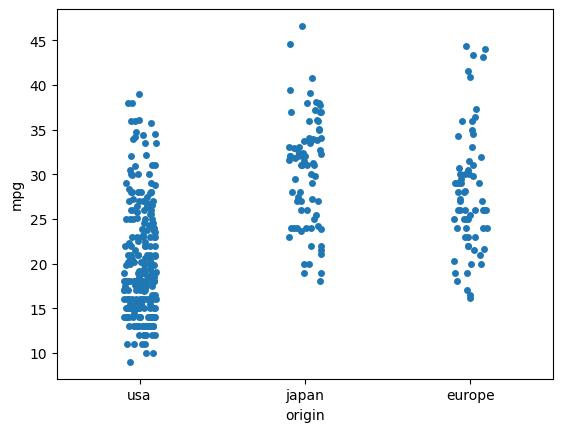
- swarmplot
- 점이 하나도 겹치지 않도록 그릴 수 있음
plt.figure(figsize=(10,4))
sns.swarmplot(data=df, x='origin', y='mpg')
catplot을 통한 범주형 데이터의 서브플롯 시각화
- seaborn 에는 다양한 서브플롯을 그릴 수 잇는 api를 제공하고 있음
- 수치형 데이터의 관계를 표현할 때는 replot
- 데이터의 분포를 표현할 때는 displot
- 범주형 데이터는 catplot
# catplot : 기본적으로는 strip 플롯을 사용함 box, violin, swarm 다 가능
sns.catplot(data=df, x='origin', y='mpg', kind='strip', col='cylinders', col_wrap= 3)
# catplot 으로 boxplot그리기
sns.catplot(data=df, x='origin',y='mpg', kind='box', col='cylinders', col_wrap= 3)
# catplot 으로 violinplot그리기
sns.catplot(data=df, x='origin', y='mpg', kind='violin', col='cylinders', col_wrap= 3)

# catplot 으로 countplot그리기
sns.catplot(data=df, x='origin', kind='count', col='cylinders', col_wrap= 3)
# catplot 으로 boxplot그리기
# 여기서는 figsize 쓰지않고 aspect=3로 크기 조절함
sns.catplot(data=df, kind='box', aspect=3)

# catplot 으로 violinplot그리기
# df 전체를 넣고 시각화 하기
sns.catplot(data=df, kind='violin', aspect=3)
'👩🏻💻 강의 기록용 > 처음 시작하는 데이터 사이언스' 카테고리의 다른 글
| 6-② 탠서플로를 통한 자동차 연비 예측하기 (데이터셋 나누기, 딥러닝 모델 만들기, 딥러닝 모델로 학습과 예측하기) (1) | 2023.09.19 |
|---|---|
| 6-① 탠서플로우를 통한 데이터 예측 (0) | 2023.09.19 |
| 05-③ 파이썬 EDA - 수치형 변수 (0) | 2023.09.17 |
| 05-② 판다스 기초와 데이터 요약, 탐색적 데이터 분석 도구 사용하기 (0) | 2023.09.17 |
| 05-① 파이썬 탐색적 데이터 분석 도구 (0) | 2023.09.12 |



